You asked, we answered: Score FAQs
 January 26, 2023
January 26, 2023
 7 min read
7 min read
 Susa Tünker, Product Manager Score
Susa Tünker, Product Manager Score
SHARE
Our community is growing and so is the amount of questions we receive! A huge thank you to everyone who dropped questions in the #score channel on the CNCF Slack, contributed to our GitHub discussions and raised GitHub issues in the last few months. We’re excited to keep the discussion going and encourage everyone to keep asking questions and sharing your ideas with us. 🚀 In this article, we’re tackling the biggest questions raised so far. Let’s dive in.
What is Score?
Score is an open source, platform-agnostic, container-based workload specification. This means you can define your workload once with the Score Specification and then use a Score Implementation CLI to translate it to multiple platforms, such as Helm, Docker Compose or Google Cloud Run. Score aims to reduce developer toil and cognitive load by enabling the definition of a single YAML file that works across multiple platforms.
What do I need to know about the Score Specification before getting started?
The Score Specification is a file that describes your workload’s runtime requirements. It is:
- platform-agnostic: The Score Specification is not tied to a specific platform or tool. As a fully platform-agnostic spec, it can be integrated with many container orchestration platforms and tooling such as Kustomize, Amazon ECS, Google Cloud Run, or Nomad.
- environment-agnostic: The
score.yamlfile captures the configuration that stays the same across all environments. This allows combining it with environment-specific parameters in the target environment. For example: Your Score spec might specify a parameterised database connecting string such aspostgres://${postgres.userna me}:{postgres.password}@${postgres.host}:${postgres.port}/${postgres.name}which is resolved in each environment the workload is deployed to by injecting the according credentials. - tightly scoped: Score describes workload level properties. It does not intend to be a fully featured YAML replacement for any platform. Instead, it draws a line between workload configuration owned by developers and platform configuration owned by operations.
- declarative: Developers declare what their workload requires to run as part of
score.yaml. The platform in the target environment is responsible for resolving individual runtime requirements. This establishes a contract between dev and ops: If the requirements listed in the spec are honoured, the workload will run as intended.
The counterpart of the Score Specification is a Score Implementation, a CLI tool (such as score-compose) that the spec can be executed against to generate the required configuration (such as compose.yaml).
Is Score really platform-agnostic given that score-compose and score-helm are the only available implementations?
Yes. score-compose and score-helm are simply reference implementations that were developed by us to demonstrate how Score could be used. Depending on your use case, you might want to write your own implementation for let’s say score-ecs or score-kustomize. You can also use one of the existing implementations and extend it according to your needs. If you’re interested in doing so, don’t hesitate to reach out. We’d be happy to collaborate.
How does Score work?
The Score Specification file is a platform-agnostic workload specification which can be run against a Score Implementation (CLI) such as score-compose or score-helm to generate a platform configuration file such as docker-compose.yaml or a helm values.yaml file. The generated configuration file can then be combined with environment-specific parameters to run the workload in the target environment.
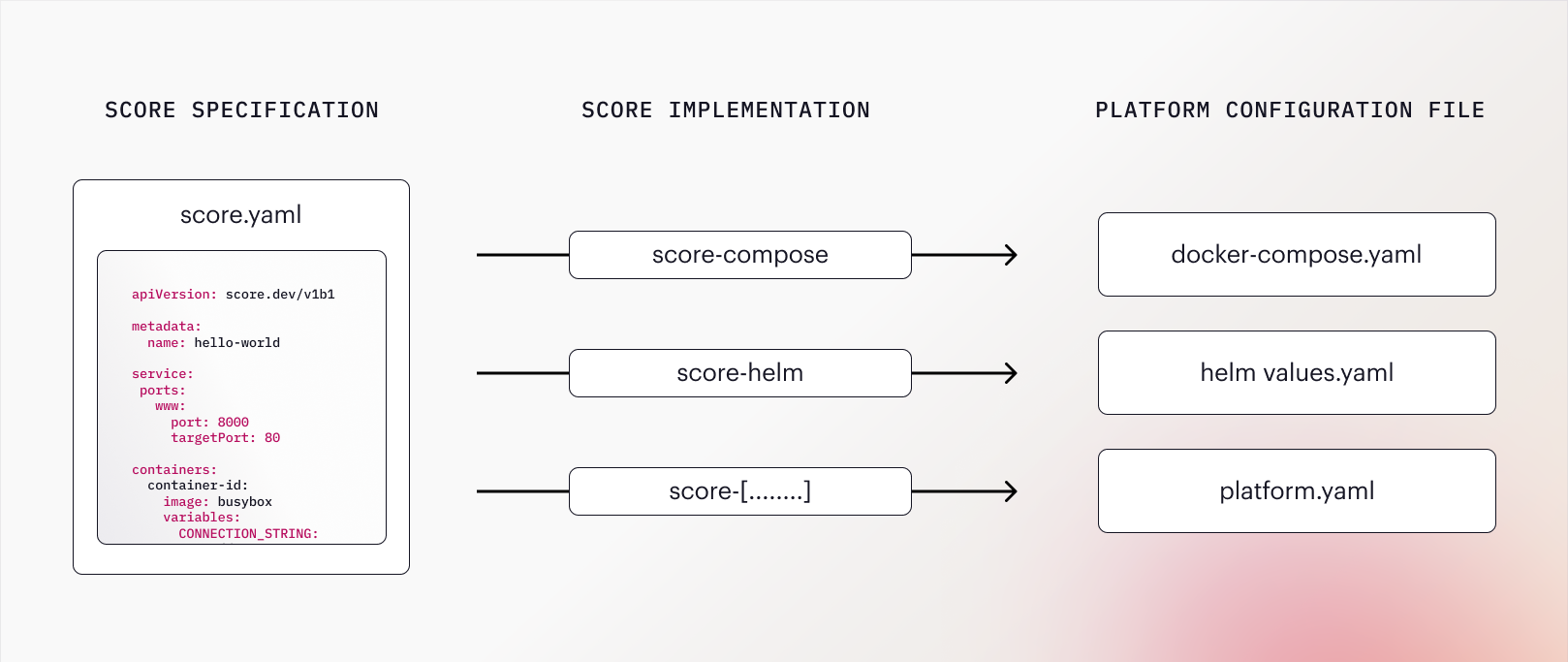
Are the configuration files generated by Score deployment-ready?
It depends on the complexity of your setup. The Hello World guides for score-compose and score-helm allow you to directly deploy a workload. In more complex use cases however, it is likely that the configuration generated by Score is combined with additional configuration provided by a platform or operations team. This allows for a clean separation of concerns between the developer owned workload related configuration and operations owned platform- and infrastructure-related configuration.
To understand what this means in practice, the following needs to be taken into account:
- Score only describes workload level properties. This means, if you’re deploying to an environment that runs on a system such as Kubernetes, you’ll likely have additional platform-specific configuration in place. For example: You might want to set up
namespace.yamlandingress.yamlfiles for the deployments. Score assumes that any configuration outside of the workload (and developer) scope is defined and managed externally, for example by an operations team. This allows you to combine the configuration generated by Score with more advanced infrastructure configuration if needed and doesn’t limit teams in leveraging the full potential of their platforms. - The Score Specification is defined in an environment-agnostic way. This means environment-specific parameters (such as variable values and secrets) need to be injected in the target environment. For example: For a database connection string such as
postgres://${postgres.username}:{postgres.password}@${postgres.host}:${post gres.host}:${postgres. port}/${postgres.name}different values need to be injected based on the environment (e.g. development, staging, production). How and from where these values are injected is up to the platform in the target environment. - Score allows users to define resource dependencies for their service. It does not declare when, how and by whom the resource should be provisioned and allocated in the target environment. It is up to the Score Implementation to resolve the resource by name, type, or any other meta information available. For example: a dependency on a postgres database could be resolved by a Docker image, a mock service, Terraform, a custom provisioning script or even a manual action - it is totally up to the platform (team).
If you’d like to learn more about the philosophy behind our way of separating concerns I recommend reading the article “Why we advocate for workload-centric over infrastructure-centric development”.
Why should I adopt Score?
Score provides a single, easy to understand specification for each workload that describes its runtime requirements in a declarative manner. The score.yaml file allows generating configuration in an automated, standardized and one-directional way. By reducing the risk of wrongly specified or inconsistent configuration between environments, we hope to foster focus and joy for developers in their day-to-day work.
Who should adopt Score?
Technically, Score can be utilised by any team running containerised applications. However, Score will be especially helpful for teams who experience the pain points it was designed to solve:
- Are you tired of fighting tech and tools when deploying your workloads from local to production?
- Does making a configurational change feel like a tedious and error-prone procedure?
- Are you often blocked and rely on other (ops) engineers to help you out?
From our experience, this is often the case in medium-sized and larger development teams that work in a continuously growing production landscape. For example, bottlenecks and knowledge silos can arise when teams deal with the adoption of new tech and tools while maintaining legacy systems.
Does it make sense for me to adopt Score in a single platform set up?
One of the main pain points that Score solves is configuration mismatch between environments that run on different platforms. For example: You might run Docker Compose locally while deploying to a Kubernetes based development environment. A Score Implementation CLI allows you to translate your Score file into all kinds of configuration formats (Docker Compose, Helm, Kustomize, ECS etc.) and thereby ensure consistent configuration. In a single platform set up this translation element won’t come into effect. Whether adopting Score makes sense for you anyway depends on your teams set up. If you’re running into config bottlenecks and are wanting to abstract away the complexity of platforms such as Kubernetes from developers, Score might be worth investigating - at the very least as a source of inspiration for your team.
In this article we looked at a set of questions related to Score, its capabilities, use cases and adoption. Is there anything we missed? Do you have a follow up question? Ping us anytime in the #score channel on the CNCF Slack or GitHub and we’ll get back to you.